8. SVM : 붓꽃 데이터 분석
페이지 정보
작성자 관리자 댓글 0건 조회 4,453회 작성일 20-02-22 10:39본문
8. SVM : 붓꽃 데이터 분석
붓꽃 데이터 다운로드
https://github.com/pandas-dev/pandas/tree/master/pandas/tests/data
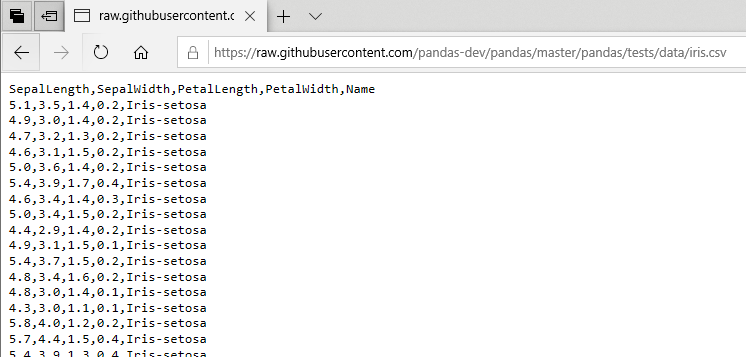
#붓꽃의 데이터를 읽어 들이기
실습1.
# -*- coding: utf-8 -*-
from sklearn import svm, metrics
import re
#붓꽃의 데이터를 읽어 들이기
csv = []
with open('iris.csv', 'r', encoding='utf-8') as fp:
#한 줄씩 읽어 오기
for line in fp:
line = line.strip() # 줄바꿈 제거
cols = line.split(',') # 쉼표로 컬럼을 구분
# 문자열 데이터를 숫자로 변환하기
fn = lambda n : float(n) if re.match(r'^[0-9\.]+$',n) else n
cols = list(map(fn, cols))
csv.append(cols)
# 헤더 제거(컬럼명 제거)
del csv[0]
print(csv[:10])
결과.
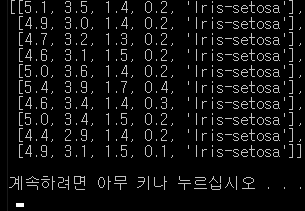
실습2.
# -*- coding: utf-8 -*-
from sklearn import svm, metrics
import random, re
#붓꽃의 데이터를 읽어 들이기
csv = []
with open('iris.csv', 'r', encoding='utf-8') as fp:
#한 줄씩 읽어 오기
for line in fp:
line = line.strip() # 줄바꿈 제거
cols = line.split(',') # 쉼표로 컬럼을 구분
# 문자열 데이터를 숫자로 변환하기
fn = lambda n : float(n) if re.match(r'^[0-9\.]+$',n) else n
cols = list(map(fn, cols))
csv.append(cols)
# 헤더 제거(컬럼명 제거)
del csv[0]
print(csv[:2])
print("---------------------")
# 데이터를 섞어주기
random.shuffle(csv)
# 훈련(학습)데이터와 테스트 데이터로 분리하기
total_len = len(csv)
train_len = int(total_len*2/3)
print(total_len, train_len)
print("---------------------")
train_data = []
train_label = []
test_data = []
test_label = []
for i in range(total_len):
data = csv[i][0:4]
label = csv[i][4]
if i < train_len:
train_data.append(data)
train_label.append(label)
else:
test_data.append(data)
test_label.append(label)
print(test_data)
print("---------------------")
print(test_label)
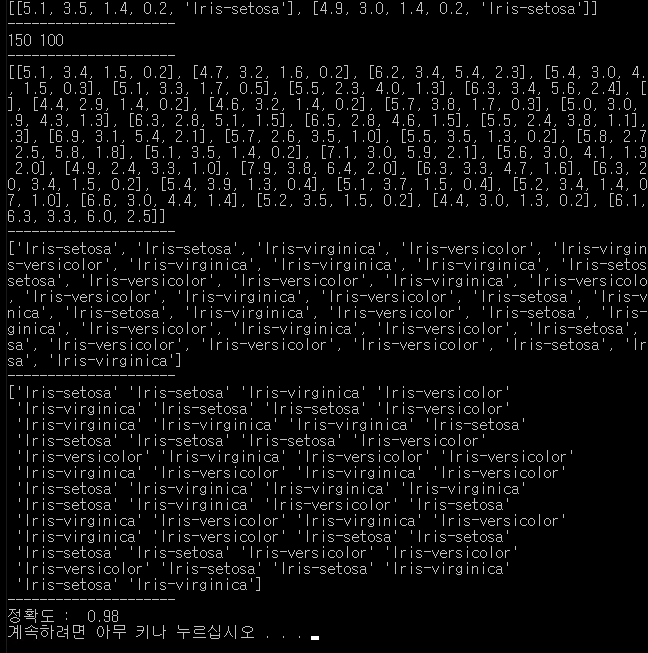
결과.
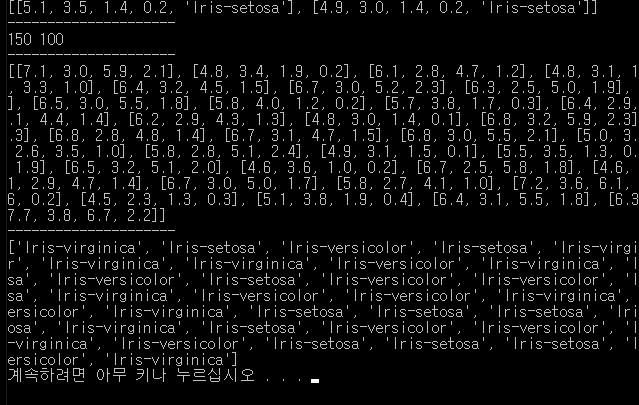
실습3.
# -*- coding: utf-8 -*-
from sklearn import svm, metrics
import random, re
#붓꽃의 데이터를 읽어 들이기
csv = []
with open('iris.csv', 'r', encoding='utf-8') as fp:
#한 줄씩 읽어 오기
for line in fp:
line = line.strip() # 줄바꿈 제거
cols = line.split(',') # 쉼표로 컬럼을 구분
# 문자열 데이터를 숫자로 변환하기
fn = lambda n : float(n) if re.match(r'^[0-9\.]+$',n) else n
cols = list(map(fn, cols))
csv.append(cols)
# 헤더 제거(컬럼명 제거)
del csv[0]
print(csv[:2])
print("---------------------")
# 데이터를 섞어주기
random.shuffle(csv)
# 훈련(학습)데이터와 테스트 데이터로 분리하기
total_len = len(csv)
train_len = int(total_len*2/3)
print(total_len, train_len)
print("---------------------")
train_data = []
train_label = []
test_data = []
test_label = []
for i in range(total_len):
data = csv[i][0:4]
label = csv[i][4]
if i < train_len:
train_data.append(data)
train_label.append(label)
else:
test_data.append(data)
test_label.append(label)
print(test_data)
print("---------------------")
print(test_label)
print("---------------------")
clf = svm.SVC()
# 학습
clf.fit(train_data, train_label)
# 테스트
pre_label = clf.predict(test_data)
print(pre_label)
print("---------------------")
# 정확도 구하기
ac_score = metrics.accuracy_score(test_label, pre_label)
print("정확도 : ", ac_score)
결과.